Untersuchungen zur Parallelisierung der Generalisierung großer Gebäude-Datenbestände
| Leitung: | Thiemann |
| Team: | Thomas Globig |
| Jahr: | 2013 |
| Laufzeit: | 2013 |
| Ist abgeschlossen: | ja |
Heutzutage stehen Geodaten in solchen Mengen zur Verfügung, dass eine Verarbeitung mit den herkömmlich zur Verfügung stehenden Rechenressourcen kaum mehr möglich ist. Dies betrifft neben der benötigten Rechenzeit vor allem den verfügbaren Arbeitsspeicher. Auch wenn die Leistung der Hardware weiterhin steigt, wächst der Umfang der zu verarbeitenden Daten in noch größerem Maße. Eine Verarbeitung großer Datenbestände kann daher nicht mehr am Stück erfolgen, eine Aufteilung der Daten ist erforderlich. Diese Aufteilung ermöglicht Berechnungen innerhalb der Daten, ohne den Gesamtdatensatz betrachten zu müssen. Aktuelle Verfahren sehen zudem die verteilte und parallele Verarbeitung großer Datenbestände vor, welche die Nutzung weitaus größerer Rechenkapazitäten als bisher ermöglicht.
Die Besonderheit von Geodaten ist deren Raumbezug. Viele Prozesse und Operationen arbeiten bei der Verarbeitung räumlicher Daten nicht objektweise, sondern verarbeiten mehrere in einem räumlichen Kontext stehende Objekte. Dies erfordert besondere Verfahren bei der Partitionierung solcher Datenbestände. Ein typischer Prozess in der Verarbeitung solcher raumbezogener Daten ist die Generalisierung. Am Institut für Kartographie und Geoinformatik (IKG) der Leibniz Universität Hannover wird für die Generalisierung von Gebäudegeometrien die Software Change eingesetzt. Auch hier sind die Grenzen der Software in der Verarbeitung großer Datenbestände erreicht.
Die vorliegende Arbeit zeigt am Beispiel der Gebäudegeneralisierung mit Change zwei Verfahren zur Partitionierung und Komposition von Gebäudedatenbeständen. Außerdem wird die verteilte parallele Berechnung dieser Daten untersucht. Dafür steht am IKG ein Rechner-Cluster mit dem Parallelisierungs-Framework Hadoop zur Verfügung.
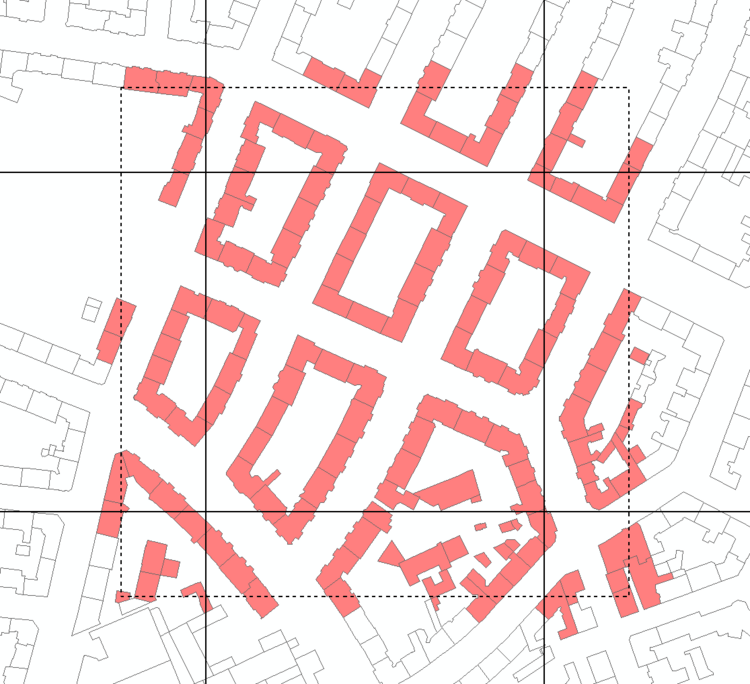
Als Partitionierungsverfahren wurden die Partitionierung durch ein Gitter mit Überlappungsbereich (vgl. Abbildung 1) sowie die Partitionierung durch räumliche Clusteranalyse gewählt. Beide Verfahren erzielen gute Ergebnisse hinsichtlich der weiteren Verarbeitung durch Change. Die verteilte Berechnung mit Hadoop erreicht einen hohen Parallelisierungsgrad. Auch wenn das eigentliche Konzept des MapReduce-Ansatzes dabei nicht umgesetzt werden konnte, wurden doch die Ziele einer parallelen Ausführung von Change und dem damit verbundenen Laufzeitgewinn erreicht. Diese verteilte Berechnung ist zudem durch die einfachen Erweiterungsmöglichkeiten des Clusters skalierbar und damit auf deutlich größere Datenbestände und Problemstellungen anwendbar.
Die Partitionierung durch ein Gitter mit Überlappungsbereich hat verschiedene Nachteile in der parallelen Bearbeitung und Komposition gezeigt. Die Verwendung eines ausreichend großen Überlappungsbereiches führt zu einer hohen Redundanz, die den Berechnungsaufwand stark vergrößert. Außerdem entstehen bei der Komposition der Partitionen zu einem Gesamtdatensatz Konflikte durch mehrfach berechnete Ergebnisobjekte (vgl. Abbildung 2).
Als effizienter Partitionierungsansatz hat sich das Clustering (vgl. Abbildung 3) gezeigt. Durch die Verwendung räumlicher Indexstrukturen kann hier eine annähernd lineare Laufzeit erreicht werden. Die Entstehung von Kompositionskonflikten ist ausgeschlossen. Im Zusammenhang einer Parallelisierung mit Hadoop konnte die Berechnung für den größten verfügbaren Testdatensatz (ca. 820.000 Gebäude) von knapp 93 Minuten auf unter drei Minuten reduziert werden. Dies zeigt das große Potential der Partitionierung und verteilten Verarbeitung von Geodaten.
Die Grenze der vorgestellten Ansätze bildet der Bedarf an Arbeitsspeicher. Auch wenn es nun möglich ist, beliebig viele Teildatensätze in kurzer Zeit zu bearbeiten, benötigt die vorhergehende Partitionierung doch eine Betrachtung des Gesamtdatensatzes, um Nachbarschaften zu erkennen. Trotz der Möglichkeit, deutlich größere Datenmengen als bisher zu verarbeiten, wird diese Grenze schnell erreicht sein. Lösungsmöglichkeiten hierfür, wie beispielsweise eine Partitionierung des Clustering, werden in der Arbeit nicht untersucht.







