Identifikation von Parkstreifen in topographischen Daten
| Led by: | Bock, Czioska |
| Team: | Simone Görler |
| Year: | 2015 |
| Duration: | 2015 |
| Is Finished: | yes |
In der heutigen Zeit verbringt ein Großteil der Autofahrer zu viel Zeit damit, einen geeigneten Parkplatz zu suchen. Dies führt nicht nur zu gestressten Autofahrern sondern auch zu einem unnötigen CO2-Ausstoß. Zur Beseitigung dieses Parkplatzsuchverkehrs können dynamische Karten erstellt werden, die zum Beispiel auf dem Smartphone als App die freien Parkplätze in der näheren Umgebung anzeigen. Dafür muss die Lage der Parkplätze bekannt sein, jedoch wird diese bei amtlichen Vermessungen nicht explizit aufgenommen. In topographischen Liniendaten sind die Begrenzungen der Parkstreifen dennoch sichtbar.
Ziel der Arbeit ist die automatisierte Identifikation von Parkstreifen anhand eines Datensatzes der Stadt Braunschweig. Dies wird einerseits mit einem selber erstellten Java-Programm umgesetzt, andrerseits wird das Programm Weka zum maschinellen Lernen genutzt. Es werden Methoden des Spatial Data Minings verwendet, genauer gesagt geschieht die Klassifikation der Liniendaten mit Hilfe von Entscheidungsbäumen und einer erweiterten Form davon, den Random Forests. Die Ergebnisse der beiden Verfahren werden auf ihre Genauigkeit hin überprüft.
Für die Entwicklung eines Java-Programms ist die Erstellung eines Entscheidungsbaums nötig. Hierfür wurden durch eine manuelle Analyse der topographischen Liniendaten sowie ihrer Attribute Merkmale gesucht, die die Parkstreifen möglichst gut darstellen. Mit diesen wurde dann der Entscheidungsbaum aufgebaut. Es wird zwischen Parkstreifen mit Längs- und mit Senkrechtaufstellung unterschieden.
Für Weka müssen die Daten vorprozessiert werden, sodass die relevanten Merkmale der Objekte als Attribute vorliegen. Insbesondere die geometrischen Merkmale müssen in numerische oder nominale Attribute umgewandelt werden, da Weka mit der Geometrie nicht arbeiten kann. Mittels dem Random Forest-Klassifikator sowie einer Kostenmatrix wurden die Objekte klassifiziert. Die Kostenmatrix wurde dabei variiert und die Ergebnisse miteinander verglichen.
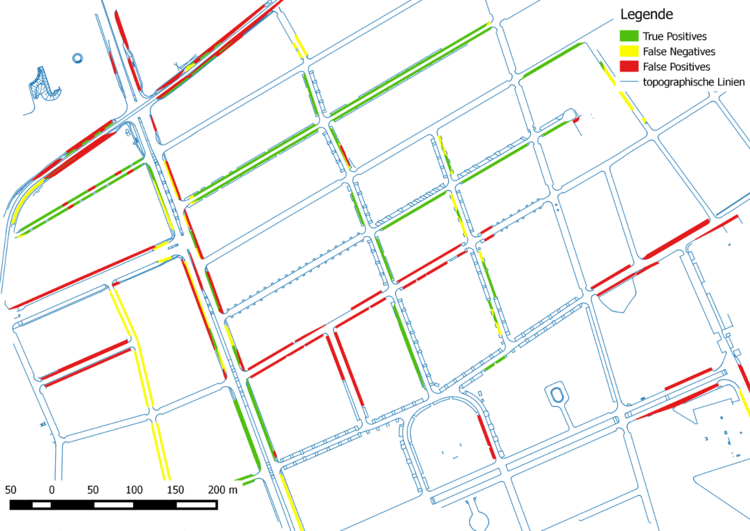
Zur Visualisierung der Ergebnisse wurden aus den als Parkstreifen klassifizierten Linien Polygone gebildet und entsprechend ihrer Richtigkeit der Klassifikation eingefärbt. In den nebenstehenden Abbildungen sind die Ergebnisse für den manuell erstellten Entscheidungsbaum und für den Random Forest Klassifikator drgestellt.
Insgesamt konnte mit dem Random Forest bei Weka bessere Ergebnisse erzielt werden, als mit dem manuell erstellten Entscheidungsbaum. Es wurden hier über 75% der Parkstreifen korrekt als solche klassifiziert, wobei von allen der als Parkstreifen klassifizierten Objekte mehr 72% auch tatsächlich Parkstreifen sind.