Klassifikation von Mobile Mapping LiDAR Punktwolken
| Led by: | Brenner, Schachtschneider |
| Team: | Anat Schaper |
| Year: | 2020 |
| Is Finished: | yes |
In vielen Anwendungsgebieten der Geodäsie, beispielsweise dem des autonomen Fahrens, gewinnt die automatische Erkennung von Objekten in (urbanen) Regionen an Relevanz. Eingesetzt werden dafür verschiedene Aufnahmesysteme, dessen Daten in Echtzeit analysiert werden müssen. Besonders gut geeignet sind dafür Light Detection and Ranging (LiDAR) Punktwolken.
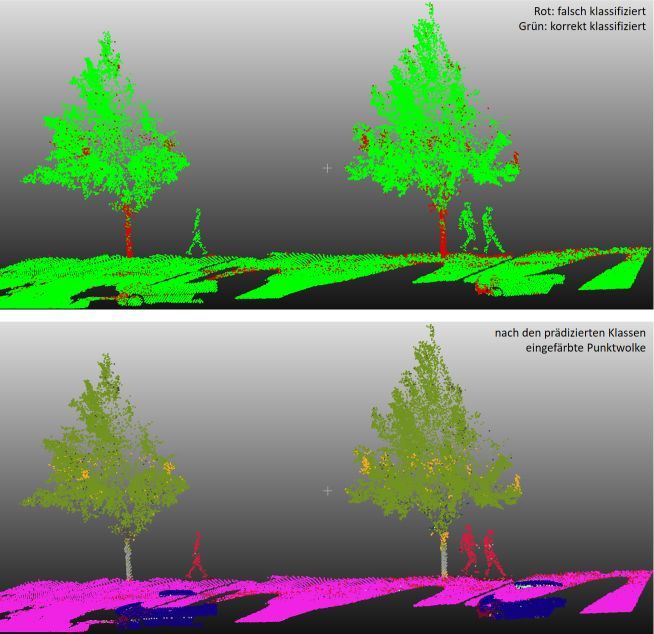
In dieser Arbeit wird die Klassifikation von LiDAR Punktwolken verschiedener Methoden analysiert und bewertet. Als Datengrundlage dienten Scanstreifen aus einer Messkampagne des Instituts für Kartographie und Geoinformatik der Leibniz Universität Hannover. Mit Hilfe der Klassifikatoren Random Forests und Support Vector Machines konnten die einzelnen LiDAR Punkte 16 verschiedenen Klassen zugeordnet werden.
Die Klassifikation mit Random Forests erreicht mit einer Gesamtgenauigkeit in Höhe von 88% bessere Ergebnisse als Support Vector Machines (79% Gesamtgenauigkeit). Die auftretenden Fehlklassifikationsarten sind in beiden Methoden ähnlich, treten jedoch mit Support Vector Machines deutlich häufiger auf. Der Großteil der Fehlklassifikationen ist nachvollziehbar und tritt auf Grund von Ähnlichkeiten in den Merkmalen sowie durch Verwechslungen auf Grund von Verdeckungen oder Überlappungen der Objekte auf. Des Weiteren haben sich beide Methoden als robust gegenüber geringen Parameteränderungen und das Zusammenfügen bzw. Entfernen einzelner Klassen erwiesen. Das Trainieren der Random Forests ohne Merkmale mit geringer Bedeutung hat sich als nicht erfolgreich herausgestellt.
Insgesamt liefert vor allem die Klassifikation mit Random Forests gute und brauchbare Ergebnisse. Support Vector Machines sind auf Grund schlechter Skalierungen für große Datenmengen eher ungeeignet. Um die Klassifikationsergebnisse weiter zu verbessern, sollte eine Verwendung zusätzlicher Merkmale wie beispielsweise die lokale Krümmung oder Omnivarianz geprüft werden. Alternativ könnten verschiedene Radien zur Nachbarschaftsberechnung genutzt und/oder eine Segmentierung der Punktwolke durchgeführt werden.